How Can I Tell What Google Indexes on My Website?

We often get questions from clients about how Google will crawl their site and what content Google will be able to “see” and therefore add to the Google search index. In an ideal world every page on your site, every download and linked document, and every single image would appear in relevant Google search results, but that’s not always the case. Keep reading to learn how you can review your website and determine what content Google will crawl and make available in search results.
Building the Google Index
Google’s ultimate goal is to “organize the world’s information”. The way they do this for online content is to build a comprehensive index of all website content and make it quickly searchable through their various services. Google has built an incredibly advanced system of “crawling” websites to ingest content, however, there are technical limitations to the crawler and other reasons why some content never makes it into Google search results.
To understand what can’t be crawled and added to this index it’s helpful to understand how the Google crawling bots work. Google discovers new URLs through a variety of ways, when a new page is discovered Google “crawls” the page, rendering it visually and downloading all the code that makes up the page. Google will find all links to other URLs and files on this page and continue to crawl and analyze that content.
In most cases Google will continue to follow links throughout this crawling process and continue to add the content to their index. However, there are some reasons why a linked URL or file won’t be crawled.
Intentional Crawler Blocking
There are many reasons why Google may not crawl a specific URL. Most of these reasons stem from technical issues that are unintentionally present in webpages. However, there are some intentional ways people block Google from crawling a URL and we will cover these first.
Blocking Content with Robots.txt
Your website may have a special text file called a “robots” file. In this file you can let search engines know what you don’t want them to crawl. Google does respect information in this file but keep in mind other search engines may not. Also, simply including a URL in your robots file may not keep the content out of Google, there are other ways the URL may be discovered by Google.
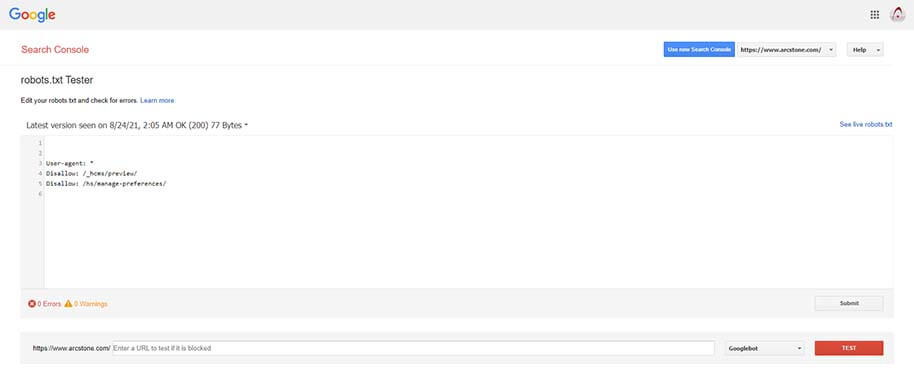
Using Google’s robots tester page to read and test ArcStone’s robot.txt file.
The reasons people choose to block some ULRs from crawlers vary and may include:
- Hiding content, like a login screen or other hidden areas
- Keeping Google from indexing new content that is still in draft form
- Keeping Google from indexing poor content that may be useful to some users but could negatively impact your SEO
- Preventing Google from indexing individual media files
You can also use a robots file to let Google know it should throttle the crawling speed to keep from overloading your website. This is a rare use case however and any well built modern website should not be negatively impacted by Google’s crawler.
Blocking Content with a NOINDEX tag
Another way to purposely prevent Google from indexing a URL is with a “NOINDEX” tag. This is a special piece of code called a “META TAG”. These tags do not appear to users but are used for controlling the behavior of search engines and browsers. Using a NOINDEX tag is a much more reliable way to prevent Google from crawling content. Google will not include pages with a NOINDEX tag in search results.
NOFOLLOW LINKS
Another reason Google may not continue to crawl through content is if the crawler comes across a “NOFOLLOW” attribute on a link. This is a special part of link HTML code that lets crawlers know the link should not be “followed” and the linking page should not be indexed.
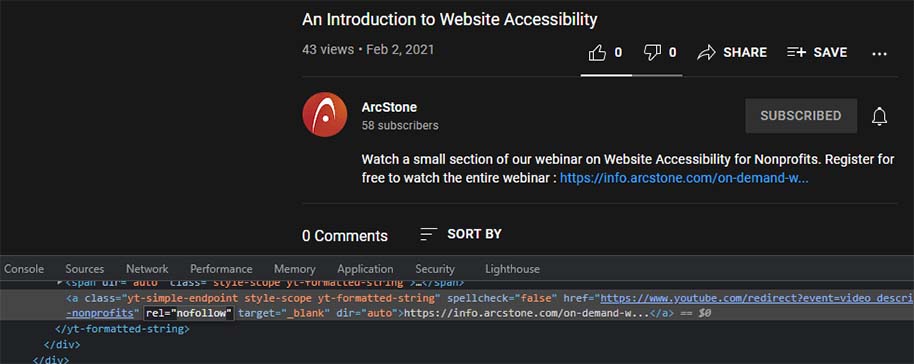
Although YouTube allows links in video descriptions you can see from the source code it’s a “nofollow link” which means the Google crawler won’t follow it.
Keep in mind most URLs have many links pointing to them and the NOFOLLOW attribute is not meant to keep content out of the Google search engine. The NOFOLLOW attribute is typically used to control the SEO benefit of a link. When website A links to website B Google interprets this as website A “vouching” for the content on website B. Many times websites wish to link out to another site but not be associated with it or seen as vouching for the quality of the linked site.
Keep in mind that although independent experiments have verified Google respects the NOFOLLOW attribute that could change at anytime without notice. Also, even if Google may not grant your website considerable SEO benefit from NOFOLLOW links, it’s still fantastic for your site to be linked to from other high quality and high traffic websites.
Registration Or Paywalls
Keep in mind Google can only crawl what’s publicly visible on your website and won’t index content behind paywalls, logins, or registration systems. Most of the time content locked behind a login or registration form is intentionally hidden from Google, but there are rare cases where you want to rank for this content. For instance, you may have a large resources library on your site but you want users to register before accessing it. In this case a possible workaround is to provide excerpts of the content that Google can crawl but keep the full content password protected.
Unintentional Crawling Issues
Errors and other specific kinds of problems with page loading is another reason why Google may not index website content. Even if the webpage looks like it’s functioning perfectly to users the Google crawler may run into underlying issues that prevent the content from being indexed.
Loading Errors
The most common error and the one most familiar to people is a 404 error. This error simply means the URL being linked to can’t be found. It could be the URL has been removed, it moved, or the URL still exists but the web server is returning a 404 “status code”. Each time a resource is requested from a web server a status code for the request is returned and in some rare cases even though the content is loading a 404 code is returned. This will prevent Google from indexing the content. This is a rare situation that sometimes occurs when website CMS systems contain underlying bugs or other issues,
Other loading problems that prevent crawling may include:
- 500 errors, which are generated by coding issues and prevent the web server from returning any content
- Redirect loops, which are generated when a page redirects to another page which in turn attempts to complete another redirect
- Timeout issues, which occur when a URL takes too long to return a status code or content, Google will only wait so long for a page to load
Dynamically Loaded Content
Another less obvious situation that may prevent Google from indexing the full content of a URL is if components of the page are dynamically loaded. What we mean by dynamically loaded content is sometimes JavaScript or another scripting language will pull content into the webpage after the initial load. This content won’t be seen by crawlers and therefore can’t be indexed.
This is more common with “single page” web applications or sites that have one long page that continues to load in chunks when people scroll down the page. The worst case scenario is if your site’s navigation is dynamically loaded. In these rare cases Google may not be able to crawl your site at all except for the homepage.
Site Speed & The Crawl Budget
Most people are aware now that site speed is a critical issue. For real users on your site snappy page loads mean happy visitors and generally more page views per session which is great for SEO. Search engines also care about site speed. Google gives each site a “crawl budget“, meaning it will only crawl as many pages as it can in a given time period. This means that if your site is very slow Google won’t get to many of you pages and that content won’t get indexed.
It’s not uncommon for very large websites to only have a certain percentage of their site crawled an indexed. Site popularity, crawlability, speed, and structure all affect how much of your site gets crawled by Google. High quality websites adhering to SEO best practices will be crawled much more often by Google and have a better chance of appearing in search results.
Linked files Crawlers Can’t Read & LARGE FILES
Google doesn’t only crawl webpages, it can actually crawl and understand a wide variety of external file types that your page content may link to. The most common file type webpages link to is PDF files. Depending on the structure of these files Google can crawl and understand the file’s contents.
However, “image only” PDF files and some other file types can’t be crawled by Google. Also, if your file is one that Google can understand but it’s extremely large that can impact the crawl budget we just covered and ultimately mean less of your site gets indexed. If at all possible avoided external files and keep all your website content in actual HTML webpages.

How To Determine What Google Can Crawl
Now that we have covered many details about how Google crawls the web and what can go wrong, lets dive into ways you can test your website to make sure Google can crawl the most content possible.
Using Your Browser
The web browser you use everyday to surf the web also has some simple tools you can use to help determine what Google can crawl on your site. For all the following examples we will use Google’s Chrome browser, although, most other browser have similar capabilities.
View The PaGe Source Code
A web page’s “source code” is the underlying code that your web browser interprets to build a visual display of the page. In most browsers you can right click or through a menu access an option to view this source code. The code will contain all the plain text content you normally read on a webpage surrounded by HTML, CSS, JavaScript and other code. Anything you can see by viewing the source code is indexable by Google.
For instance, if you have text in a slide show, accordion component, or other visual mechanism that doesn’t show content until a user interacts with it, you can view the source code to determine if Google will index that content. Simply bring up the source code and search for the text. If you can find the text in the source code than so can Google.
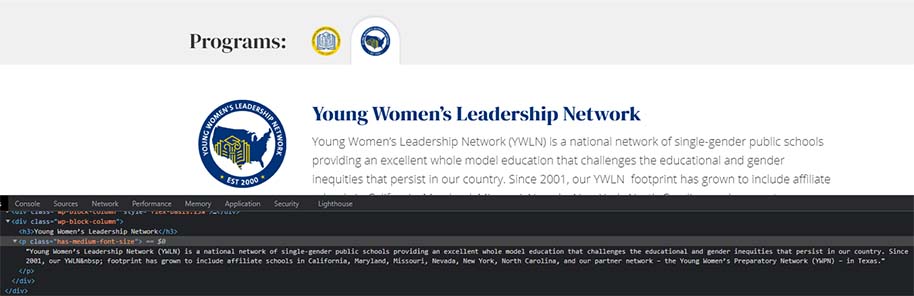
Although this page has an area with two tabs of content it’s all indexable by Google because we can see the content in the page source code.
View The Page LOading Information
We covered status codes earlier, and while it’s rare that a website returns the wrong code for a page load it sometimes happens. Your browser should have a simple way to check the status code of a webpage.
There are browser plugins that make this a little easier but none are required. If you right click in Chrome on any webpage there is an option for “inspect”. Clicking this will bring up the Chrome developer tools. Click the “network tab” then reload the page. A large list of information will appear once the page has loaded. This list contains all the individual network requests that are needed to build the page. In this list will be the main URL of the page. Clicking on it will bring up details about the request including the status code. This code should be “200”. If it’s not Google may not be able to index this page.
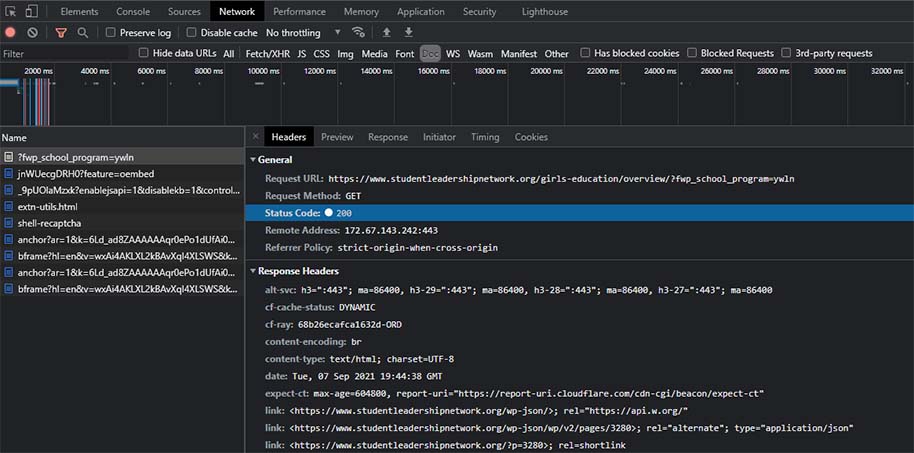
Using the network tab in Chrome developer tools we can see information about the page load.
Using Google Tools
A better option than a web browser for investigating your site’s crawlability is the free tools Google offers. While Google analytics is an excellent tool for analyzing and reporting on your website’s traffic and usage it’s not a tool for reviewing crawler information. There are three main Google tools that can help you take a deep dive into how Google is crawling your site.
Google Search COnsole & The URL INspection Tool
Google search console is a free tool like Google analytics, however, you don’t “install” it like Google analytics so there’s no need to worry about not having it setup already. Search console requires you to verify ownership of your website and then you’ll have a sneak peak inside of the Google index and access to some very useful tools.
The “index” area of search console is where you will find reports on how your site is indexed and tools for managing your sitemap. The “coverage” reports in this area will show you how much of your site is in the Google index, any crawl errors Google has experienced, and other critical information. You can click on any URL in the coverage area and see important details like when it was last crawled and if it’s currently in the Google index.
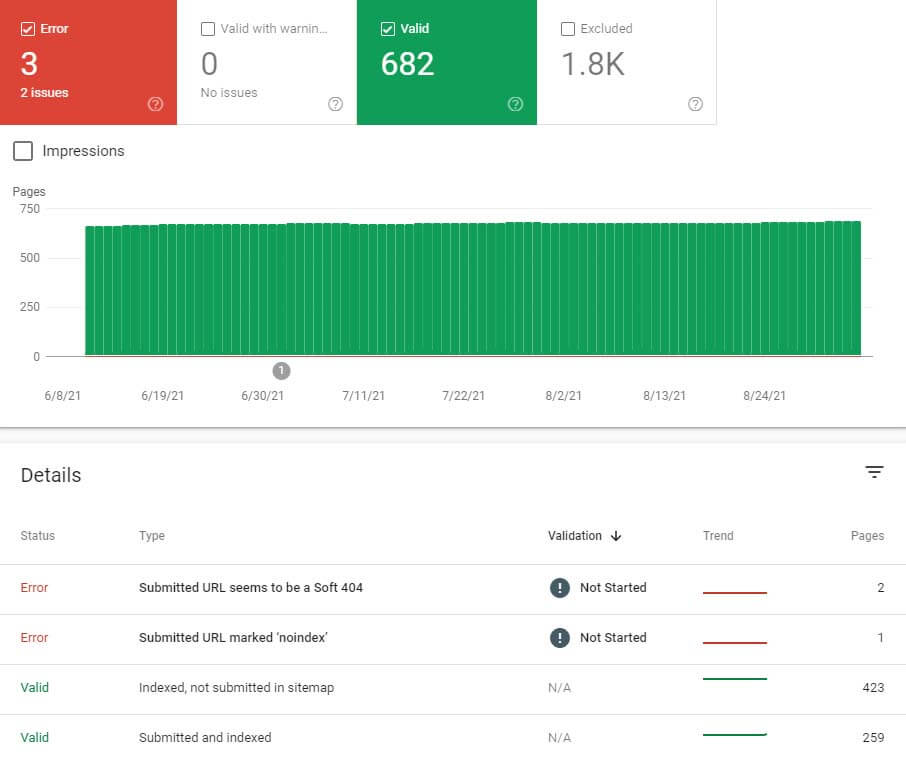
The coverage report area of Google search console which provides useful information about what Google has found attempting to crawl your website.
The “sitemap” area of coverage is where you can submit and manage your sitemap XML files. Sitemap files are not meant to be human readable but are specially formatted XML files that give Google information about your website URLs. It’s highly recommended you submit a sitemap file to Google. This will increase the chance Google will index more of your URLs and lets you let Google know which pages are more important and how often specific pages are expected to be updated. Most modern website CMS systems like WordPress automatically generate sitemap XML files. If you are unsure how to find these sitemap URLs speak with your website developer.
At the top of Google’s search console website is the “URL inspection tool”. You can enter any URL from your website into this box and bring up a report of information from the Google index. This is the definitive way to check if a page will appear in the Google search engine and what content from the URL is available to Google.
To “see what Google sees” when this URL is crawled you can click the “view crawled page” link and bring up the page’s content and code exactly like it will be presented to Google when the crawler hits the same URL.
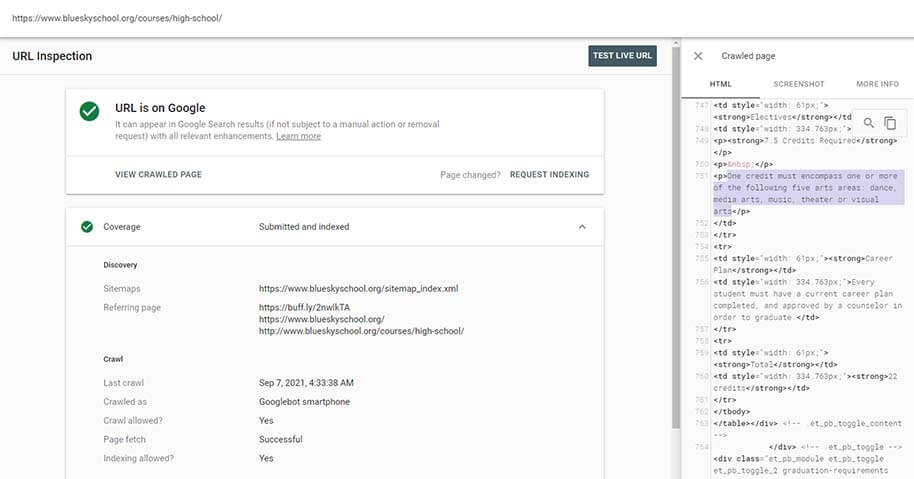
Using the URL inspection tool in Google search console we can verify specific content is being crawled and indexed by Google properly.
From the URL inspection tool you can:
- Check if a URL is in Google
- See a full crawl and index report including when the URL was last crawled
- Test the live URL and see what content is indexable by the Google crawler
- See if the URL is mobile friendly
- See if Google has detected and indexed any SCHEMA markup in your content
- Request the URL be recrawled after you’ve made corrections or updates
Google Rich Results Test Tool
Google also provides a separate tool for testing the SCHEMA implementation on your webpages. SCHEMA is special code that helps search engine understand data driven content on your website. SCHEMA code is usually recommended for events, articles, job postings, products and other content that Google provides special search results for in the Google search engine.
The rich results tool will fetch the URL you enter as the Google crawler and display information about the SCHEMA markup it finds. If you have errors or other issues in the markup this is a handy tool for discovering and correcting problems.
Google Page Speed Insights
Another very useful free tool from Google is page speed insights. This is not a tool directly related to the search index and crawling your site, but it can be very useful for improving the crawlability of your website by discovering page performance issues.
You can enter any URL into page speed insights and Google will fetch the page with both their mobile and desktop crawlers. The site provides reports for both mobile and desktop page performance, and you can drill down into details about any issues that are discovered and see Google’s recommended steps to improve your site speed.
If you find Google isn’t indexing much of your site or taking a long time to crawl new content do some testing in page speed insights to see if the Google crawler is experiencing extremely slow speeds accessing your URLs.
Crawling Evolves
I hope these tips help you understand how Google crawls your site and gives you some tools for making your website highly indexable. Also, keep in mind the Google crawler is constantly being updated. Google makes around 300 changes per year to the search engine and some of these updates can significantly change how your site appears in search results.
Google won’t explicitly say how or what they are changing in their systems but it’s not a bad idea to keep an eye on the documentation area of Google Search Central to get the latest tips on optimizing your site for Google.